
Privacidad en tiempos del Big Data
Hay algo intimo nuestro, propio, que vive en la nube. Una huella digital en el sentido estricto de la palabra. Nos preguntamos: ¿quién es el dueño de esa huella? En la época del Big Data, sin querer vamos entregando parte de esa identidad hasta que ya no nos pertenece. En esta nota exploramos algunos aspectos de la noción de privacidad de datos personales en sistemas interconectados en red y los desafíos (matemáticos) que se enfrentan para la protección de ellos.
La ley 19.628 de la “protección de datos de carácter personal” define en su artículo No2 que son “datos de carácter personal o datos personales, los relativos a cualquier información concerniente a personas naturales, identificadas o identificables”, y que son “datos sensibles, aquellos datos personales que se refieren a las características físicas o morales de las personas o a hechos o circunstancias de su vida privada o intimidad, tales como los hábitos personales, el origen racial, las ideologías y opiniones políticas, las creencias o convicciones religiosas, los estados de salud físicos o psíquicos y la vida sexual”, y que el “Titular de los datos [es] la persona natural a la que se refieren los datos de carácter personal”.
Imagine el siguiente escenario: una base de datos contiene nombres, números de cuenta corriente asociadas y listas de productos que cada persona ha comprado en la farmacia en el último año. Otra base de datos contiene nombres, direcciones y listas de productos del retail que cada persona ha adquirido en el último mes. Si su nombre aparece en las dos bases de datos, entonces la empresa donde usted trabaja puede deducir que usted probablemente va a pedir licencia por embarazo. ¿Suena imposible o plausible?
Un hecho bastante similar fue reportado el año 2012, atribuido a la empresa norteamericana Target (basada en Minneapolis, Montana): un estudio de Big Data habría identificado a una persona a partir del análisis de hábitos de compra de clientes embarazadas, tanto en el retail como en la farmacia. (Ver https://www.forbes.com/sites/kashmirhill/2012/02/16/how-target-figured-out-a-teen-girl-was-pregnant-before-her-father-did)
Aunque inverosímil y posteriormente refutada, la anécdota ilustra bien el fenómeno de pérdida de anonimato y violación de privacidad cuando se cruzan bases de datos distintas y los peligros que conlleva. ¿Lo hacen las compañías? Si pueden, lo harán y es tarea del marco legal y jurídico prever que ello no ocurra.
Desde la mirada académica podemos estudiar qué medidas proponer para preservar adecuadamente la privacidad de los datos personales y, con ello, minimizar los riesgos asociados al habitar los innumerables espacios virtuales (léase redes sociales como Twitter, Facebook, Instagram), productos y servicios web (como Google y Amazon) y otras bases de datos del retail, servicios públicos, salud, etc.
¿Qué es privacidad? Según la Real Academia de la Lengua española, privacidad es el ámbito de la vida privada que se tiene derecho a proteger de cualquier intromisión. ¿Y qué es la vida privada? El mismo diccionario propone que privado es 1. aquello que se ejecuta a la vista de pocos, familiar y domésticamente, sin formalidad ni ceremonia alguna, 2. particular y personal de cada individuo y 3. que no es de propiedad pública o estatal, sino que pertenece a particulares.
Podemos decir, pues, que la privacidad de un dato es una función que depende de los valores de:
• Grado de intrusión o individualidad (significa intervención o acceso potencial de terceros)
• Proporción o número de personas/entidades que conocen el dato. Este último parámetro es, sin embargo, una magnitud incierta pues es más difícil de estimar y no está completamente disociado del grado de intrusión.
Por lo tanto, en una primera aproximación, la protección de la privacidad dependerá fundamentalmente de qué tanto podemos lograr que sea el titular de los datos el que determine el grado de intrusión aceptable para uno - o más - de sus datos privados. La ley 19.628, en concordancia con un conjunto de otras leyes y normas de otros países, alude al rol que juega la autorización (consentimiento) como acto jurídico para que un dato privado pase a ser de dominio público y en qué cuantía. El consentimiento debe hacer explícitas las fronteras de hasta donde permite el titular que se expanda el grado de intrusión. En cambio, lo particular y personal de cada uno, que no desea ser transferido al dominio público de ninguna manera, cae en el ámbito del secreto y que por tanto no es de propiedad pública o estatal.
La primera y más evidente forma de mantener algo secreto es ocultarlo, de modo tal que cualquier observador casual o malicioso tenga grandes dificultades para develar el secreto. Esto se logra con Criptografía clásica, un conjunto de técnicas de protección de datos que se puede visualizar como una caja fuerte virtual en donde se guardan datos bajo llave. Acá existen dos grandes paradigmas: La simétrica de una sola llave y la asimétrica o de llave pública y privada. La primera, utiliza la misma llave para cerrar y abrir, en cambio la segunda utiliza una llave para cerrar (la pública) y otra para abrir (la privada).
La mayoría de los métodos actuales de cifrado son híbridos, es decir una combinación de cifrado simétrico con uno asimétrico, por cuanto las complejidades matemáticas de uno y otro son fundamentalmente diferentes. Las transacciones seguras con el banco, por ejemplo, utilizan esquemas híbridos para cifrar la comunicación entre cliente y banco.
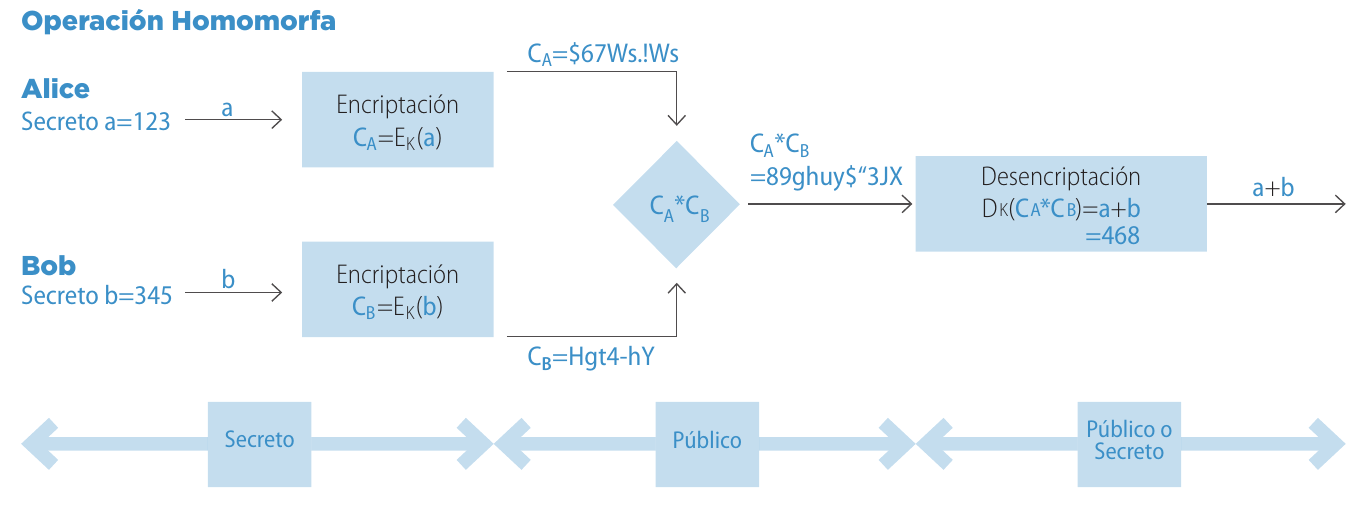
Una manera ingeniosa es dividir el secreto en partes, lo que da origen a la llamada “computación segura multi-parte”. La idea es combinar métodos criptográficos modernos con cálculos distribuidos que preserven privacidad. A esto se agrega la “criptografía homomorfa”, una técnica que permite hacer operaciones matemáticas sobre datos cifrados. La combinación de criptografía homomorfa con computación segura multi-parte promete ser particularmente útil para – por ejemplo – las votaciones electrónicas, recuerde que el voto es individual y secreto.
Por último, una técnica útil que sólo recientemente ha comenzado a ser “matematizada” lleva por nombre “Privacidad diferencial”. Si una base de datos que contiene registros pertenecientes al individuo X se utiliza para generar una información Y determinada, se dirá que es “diferencialmente privada” si la información que se obtiene excluyendo los datos de X es indistinguible (estadísticamente) de Y. Los datos anonimizados son una contribución en ese sentido.
Así, si por ejemplo una base de datos médica contiene el registro “María José, 67 años, rut 1234567-8, diagnóstico diabetes” ese registro no está anonimizado, pues su filtración identifica de manera única a María José, que tiene diabetes. Por otra parte, si la base de datos sólo contiene el registro “Primer paciente, 67 años, diabetes” no será posible – en principio - revelar los datos de María José.
Un primer conjunto de recomendaciones en época de Big Data puede, por lo tanto, tomar la siguiente forma:
A.- Encripte sus datos: si sube información sensible a “la nube”, cerciórese que sus datos están cifrados: usted no sabe quién accede y eventualmente está revisando su información en el servidor que aloja sus datos. Si guarda datos sensibles en su computador o celular, que estén en algún sector encriptado.
B.- Difumine su perfil virtual: evite entregar información sensible a cambio de “descuentos” u otros fines, si no le han explicado qué harán con sus datos y usted no ha consentido expresamente su uso. El cruce de distintas bases de datos puede conducir a una pérdida (divulgación) de sus datos sensibles o protegidos.
C.- Anonimize: si va a manejar datos de terceros, acuda a la anonimización. Usted verdaderamente no necesita saber la identidad de sus clientes si sólo quiere saber si les gusta la marca A o la marca B. Si va a pedir datos sensibles, pida un consentimiento informado y destruya los datos cuando ya no los necesite.
Fuentes de Información: Si desea saber más de Criptografía, le recomiendo el libro de Simon Singh “Los códigos secretos” Editorial Debate, 2020 (disponible en Amazon).
Para computación multi-parte, vea este blog de Gonzalo Álvarez Marañón (2019), que está bastante bueno: https://empresas.blogthinkbig.com/computacion-segura-en-la-nube-datos-cifrados-sin-descifrarlos-parte-1/ y https://empresas.blogthinkbig.com/computacion-segura-en-la-nube-datos-cifrados-sin-descifrarlos-parte-2/
Para privacidad diferencial puede leer también de Gonzalo Álvarez Marañón (2020) el blog: https://empresas.blogthinkbig.com/privacidad-diferencial-google-apple-la-usan-con-tus-datos/
Por último, si desea tomar un curso, puede venir a mi asignatura de pregrado “Criptografía y Seguridad” del Departamento de Ciencias de la Computación e Informática (DCI) de la Universidad de La Frontera o bien inscribirse en nuestro Magister de Ingeniería Informática y beneficiarse de los módulos de Calidad y Seguridad, así como el de Modelación de Sistemas.
Dr. Julio López Fenner
julio.lopez@ufrontera.cl
Departamento de Ciencias de la Computación e Informática
Cibersecurity Workgroup, Centro de Modelación y Computación Científica
(CEMCC)
Publicado originalmente en revista Nuestra Muestra